Supply Chain
Distribute Your Product to the Right Locations Based on Demand, From the Initial Allocation Through Final Replenishment.
Know What to Move, Where to Move It, And When.
Churchill’s Demand Forecasting solutions help Supply Chain leaders anticipate seasonal demand, allocate inventory with confidence, and replenish based on data — not guesswork. With advanced AI models built for Seasonality, Allocation & Sell-Through, and Replenishment, we help you keep inventory lean, responsive, and aligned with business objectives.
Seasonality
Predict demand with precision to maximize seasonal performance and minimize waste
Allocation & Sell-Through Forecasting
Make smarter initial allocations and in-season inventory moves
Inventory Replenishment
Shift from reactive strategies to proactive planning — keeping shelves stocked and inventory balanced
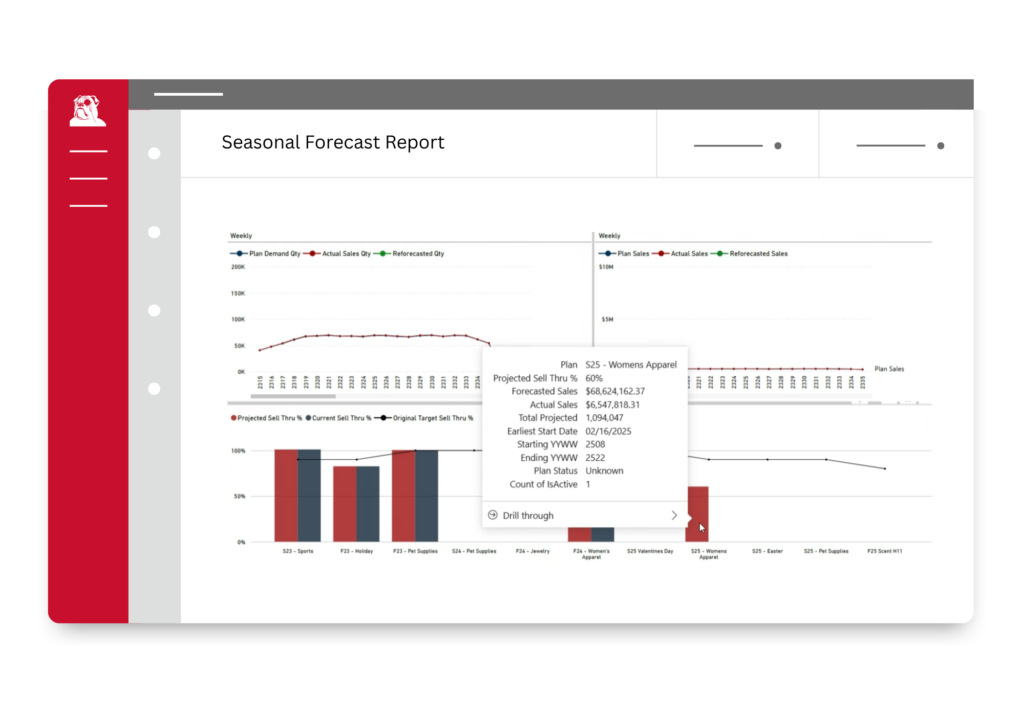
Seasonality
Churchill’s Seasonality solution helps supply chain teams generate accurate seasonal profiles through our proprietary Profile Cluster Builder™ (PCB). By analyzing item attributes and category behavior, PCB supports localized forecasting that aligns inventory with future demand across the product lifecycle. This enables more efficient seasonal allocations, reduces overstock and early sellouts, while ensuring that assortments are optimized down to the store level.
- Build seasonal profiles at every level of the item and store hierarchies
- Improve assortments by getting the right mix of products to achieve business objectives
- Update profiles on a regular basis as consumer demand changes
Allocation & Sell-Through Forecasting
Churchill’s Allocation & Sell-Through Forecasting solution leverages the Short Life Cycle Demand Forecaster™ (SLC) to optimize initial allocations and in-season inventory decisions. By forecasting item-level demand at the store level, retailers can minimize stockouts, reduce markdowns, and maximize sell-through at every location — especially for seasonal and short lifecycle products.
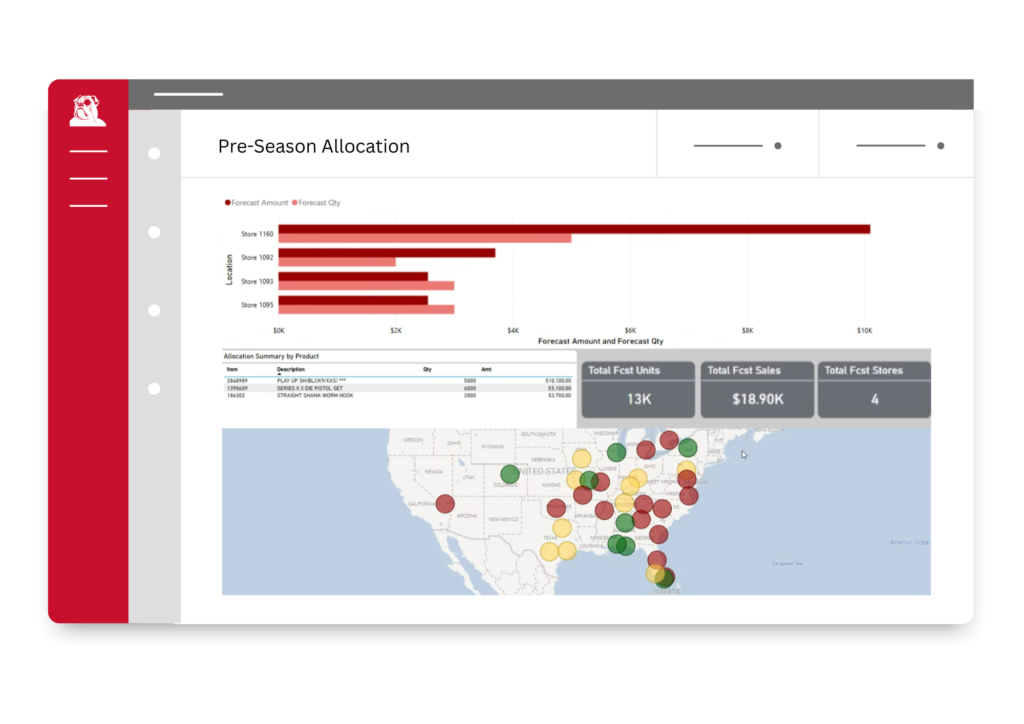
- Higher Confidence in First Allocations
- Better Alignment Between Merchandise Planningng and Supply Chain
- More Predictable Sell-Through Performance
- Smarter Use of Limited Inventory
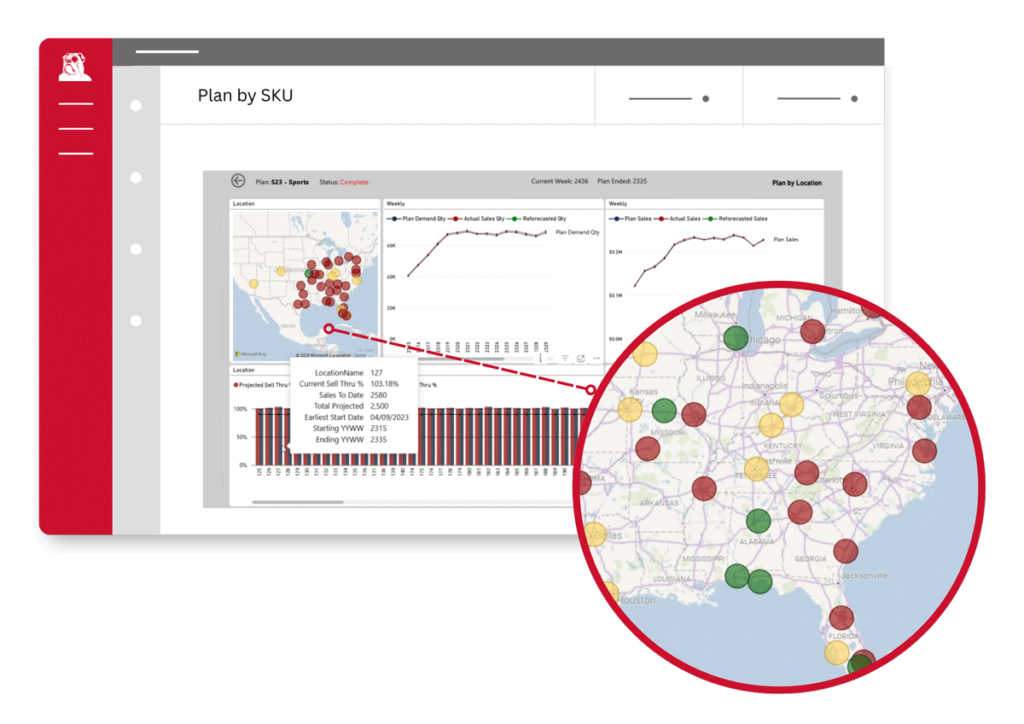
Inventory Replenishment
Churchill’s Inventory Replenishment forecasting solution transforms replenishment into a proactive, demand-driven process. Purpose-built for large, complex retail networks, it uses the Replenishment Demand Forecaster™ (RDF) to generate accurate, store/SKU-level forecasts and model stock targets. By aligning replenishment decisions with true demand signals, it reduces excess stock, prevents stockouts, and improves inventory turnover.
- Demand-Aligned Reorders
- Store/SKU-Level Precision
- Improved Inventory Turnover
- Scalability for Complex Retail
- Reduced Manual Intervention

What’s Really Holding Back Your Inventory Performance?
Explore how AI-based Demand Forecasting improves three critical Supply Chain functions: Seasonality, Allocation & Sell-Through, and Replenishment. This eBook offers a practical breakdown of how AI helps reduce stockouts, cut excess, and keep your network aligned with demand.